My First CTF Write Up
SANS Hackfest 2020
I have always wanted to participate in a CTF. I knew it would be a great way to learn but I have always been intimidated. I was always afraid I would spend days attempting to hack away at something only to end the game dead last, with zero flags
However, in 2020 I attended a virtual conference SANS Hackfest. I heard about a few free CTF's that would be open during the conference. The speaker mentioned the different events and he described BootUp as a great start for beginners so I gave it a shot. The following is the write up of my first CTF.
* Spoiler Alert * It seems I did come in dead last but I lost nothing. I gained an amazing experience, had fun, and learned quite a bit. So let’s dive into it.
BootUp 2020
This CTF was jeopardy style separated into categories: binary exploitation, forensics, networking, and web. Each challenge was assigned points relative to the difficulty level.
Web
WE01 - URL Fuzzing: 100pt
Our first web challenge starts here.

Figure 1: WE01
The hint said to “think of places you could get a list of common directories to check for”. I tried looking at /robots.txt by appending this to the end of the URL but it seemed to take me back to the same destination web page.
I knew this was not necessarily going to take me to a list of common directories but at first, I thought it may take me to a list of directories that were either allowed/disallowed
This challenge is called URL Fuzzing. URL Fuzzing is essentially making numerous requests to a server attempting to find hidden paths/files/directories in hopes of discovering hidden content or content that is not obvious to web page viewers.
The requests are built using a list of commonly known directory/file names, the tool would traverse the list sending many requests and logging responses. If the response is a 200, then this is reported back to the user.
This would give me an idea of paths we can access on the site. The results of the scan showed us a new route /sample/ returning a 200 response.

Figure 2: Route Results
I navigated back to the webpage and typed /sample/ after the URL. Lo and behold we seemed to have found it.

Figure 3: proof-weo01
Contents of flag.txt: bustING_direTORies_8918
WEO3 - Web Crawling: 100pt
In this exercise, we start out with a new web page.

Figure 4: WE03
In this challenge, we are instructed to navigate to the URL and try to find the flag. I decided to take a similar approach to the one I took before. I attempted to navigate to /robots.txt .

Figure 5: robots.txt
Figure 5 displays instructions from robots.txt: User-agent: * Disallow: /61829201829023.html indicating that the server does not want any agent to access /61829201829023.html this tells search engine crawlers to ignore the path stated. Since we can view robots.txt, we can see the path that we “should not navigate to”. So I typed in our URL followed by the “disallowed path” and here we can see our flag!

Figure 6: WE03 Flag
WM03 - API's: 250pt
This next challenge's hint tells us to get the flag from the API. So we check it out, following the URL to

Figure 7: WM03
I decided to navigate to the URL and proxy through Burp Suite to look at our requests' structure. I noticed that upon requesting the web page from the image above, a POST request was made to an API route /stag/wm03 for user information. I assumed this request determines the user data displayed on the initial web page (User/Age):

The response that we see:

Notice this response is the data used on the web page to display user data "User" and "Age". I tried changing the {"getUser": 1} parameter to {"getUser": 2}, just to observe what kind of input the API expects. I was curious if I could pass another number in the parameter to receive another user or if I could possibly pass strings and create another query. I was looking for something interesting that would tell me what parameters the API allows. I received a 200 response but a not found error with each attempt.
I tried changing getUser to getFlag and sent off a similar POST request with these changes. I received an error response No API Token.
So I decided to try to query for the token itself. I wasn't confident I would receive the API token but I was curious to see what response I might get. I received a list of possible commands.
My POST request:
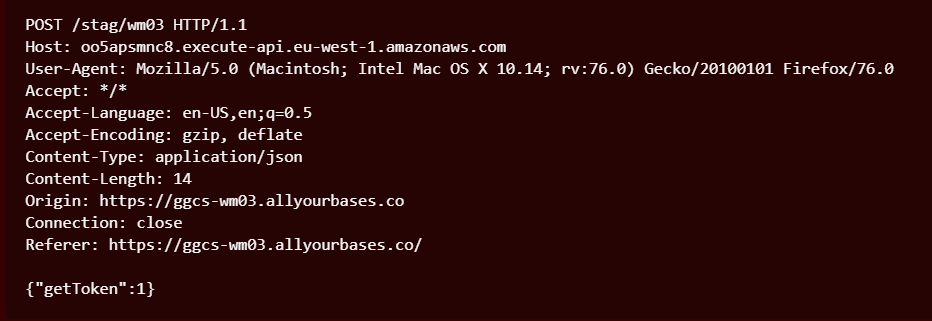
Server Response with command options:

So from here, I decided to try the config command.

From here I sent a POST request passing the API token and the getFlag argument.

And finally, receive the response we have been looking for:
